Generative AI 年會小聚分享
// 在臺下
每一場都帶回很多點子
回家搞砸嘗試。

// 所以今天想分享
斑馬手冊
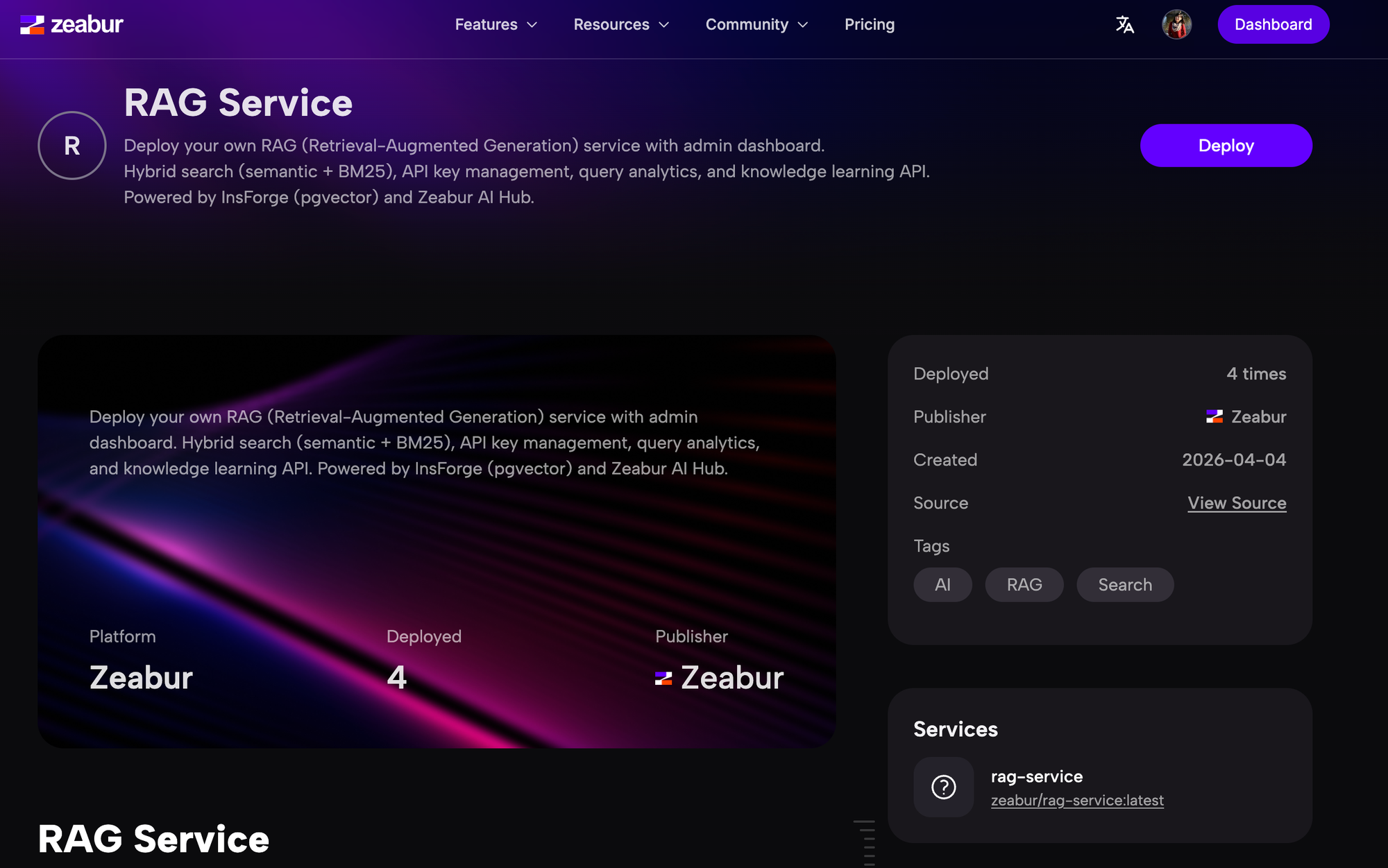
進化史斑馬手冊進化史:從 Repo 到團隊的知識基礎設施
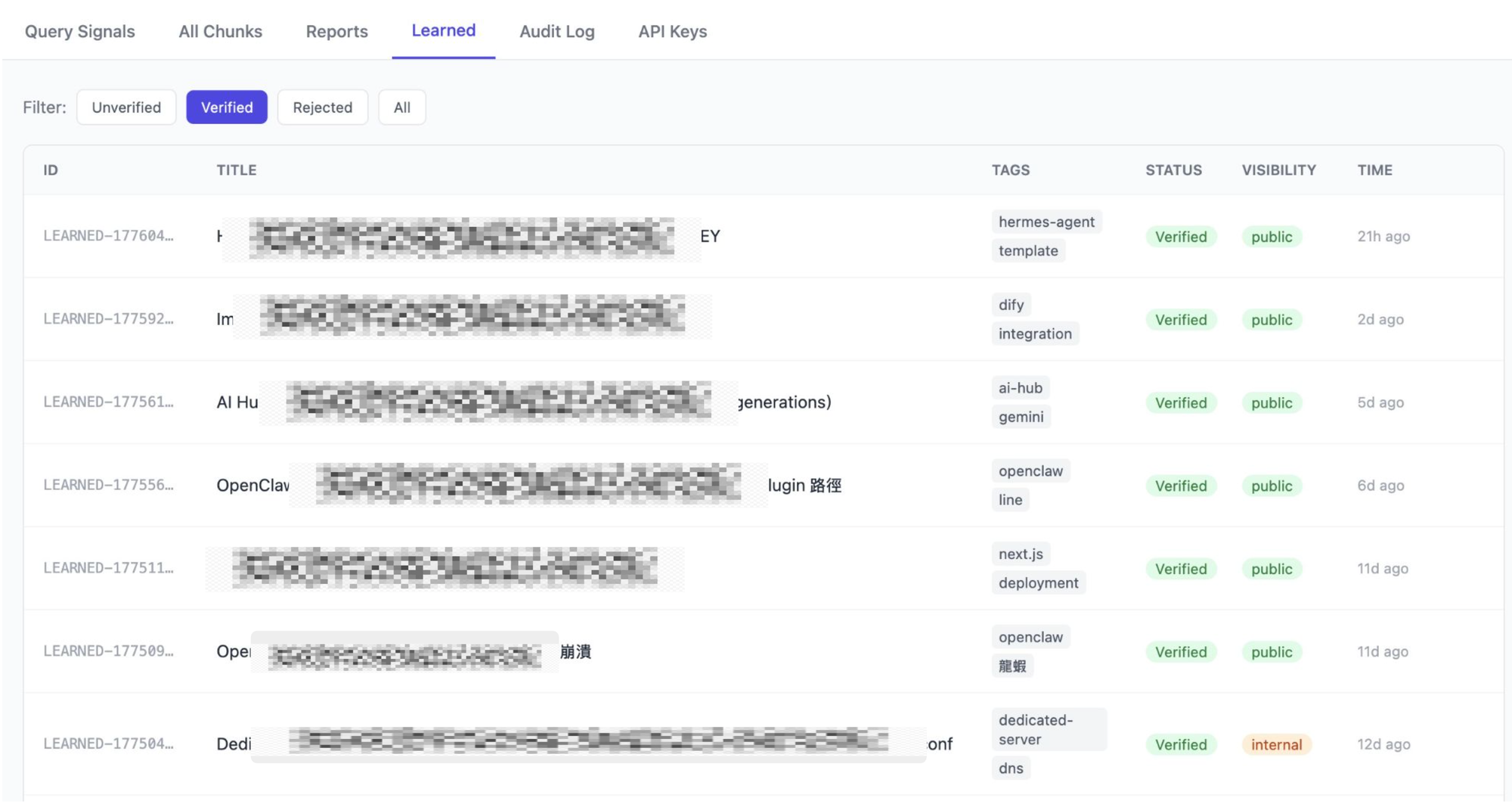
已驗證 · 進入循環
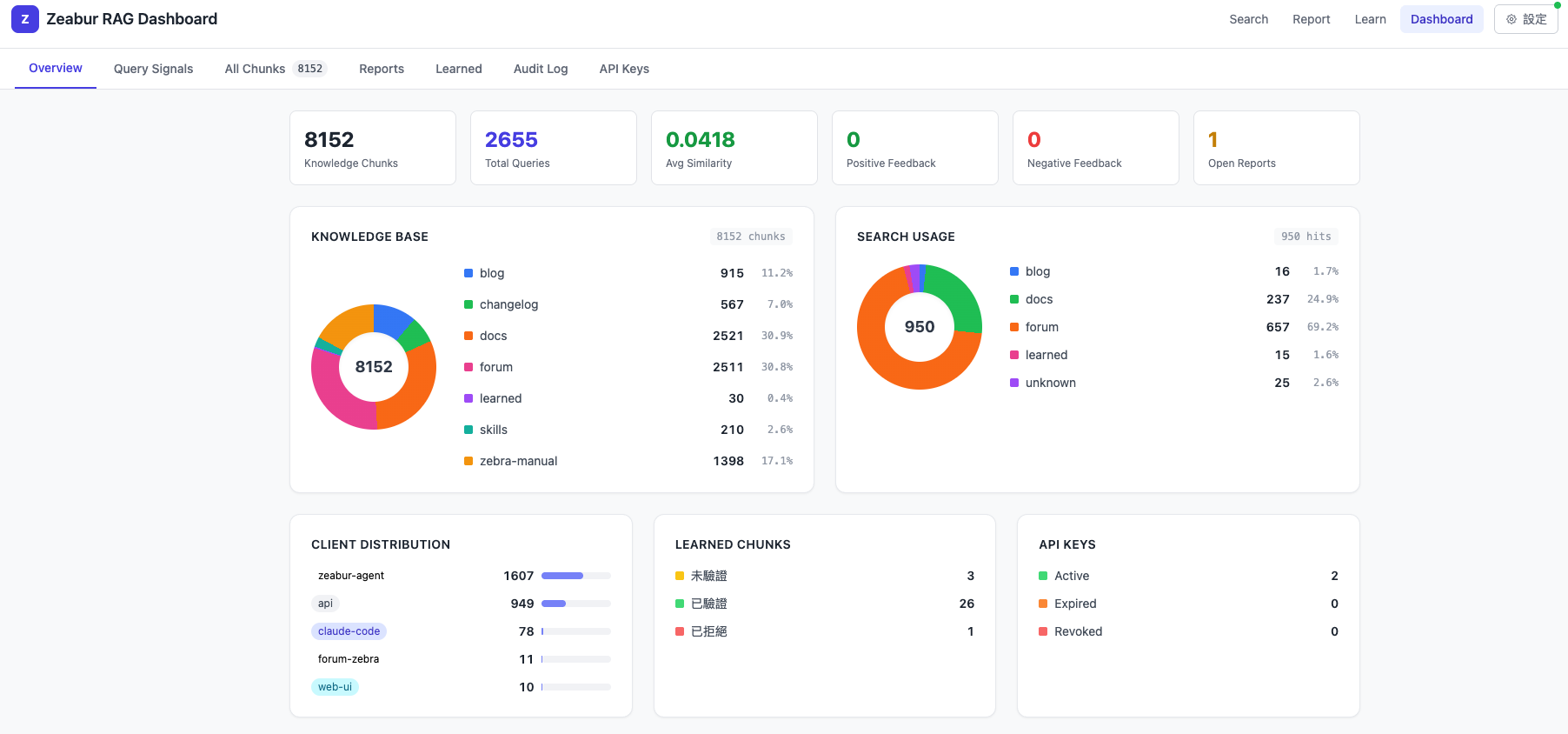
同樣的 RAG 架構、同樣的後台,一鍵部署到自己的環境,剩下時間花在迭代知識本身。
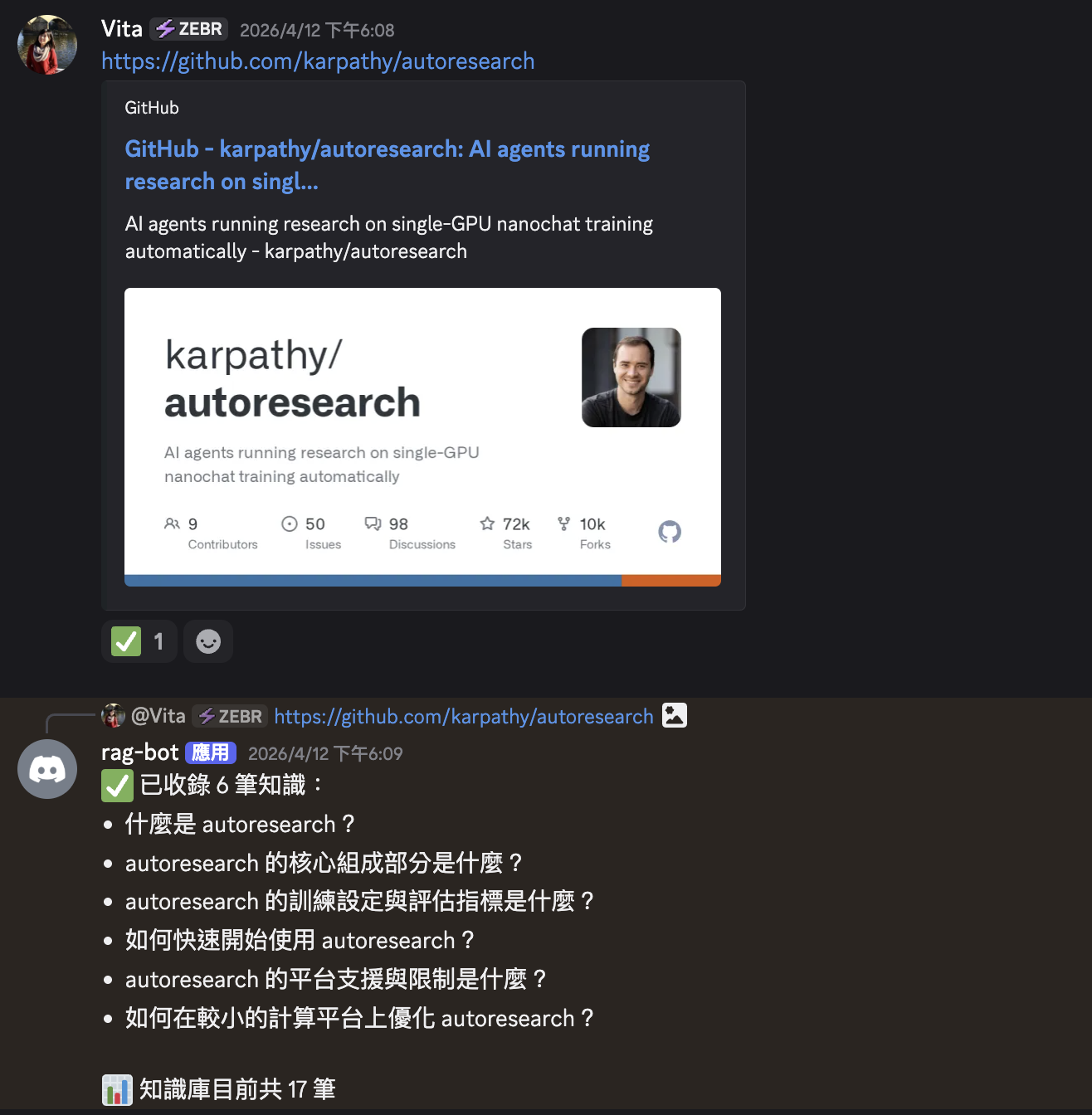
滑手機看到好東西,丟到平常就在用的 Discord 頻道——剩下交給 rag-bot。
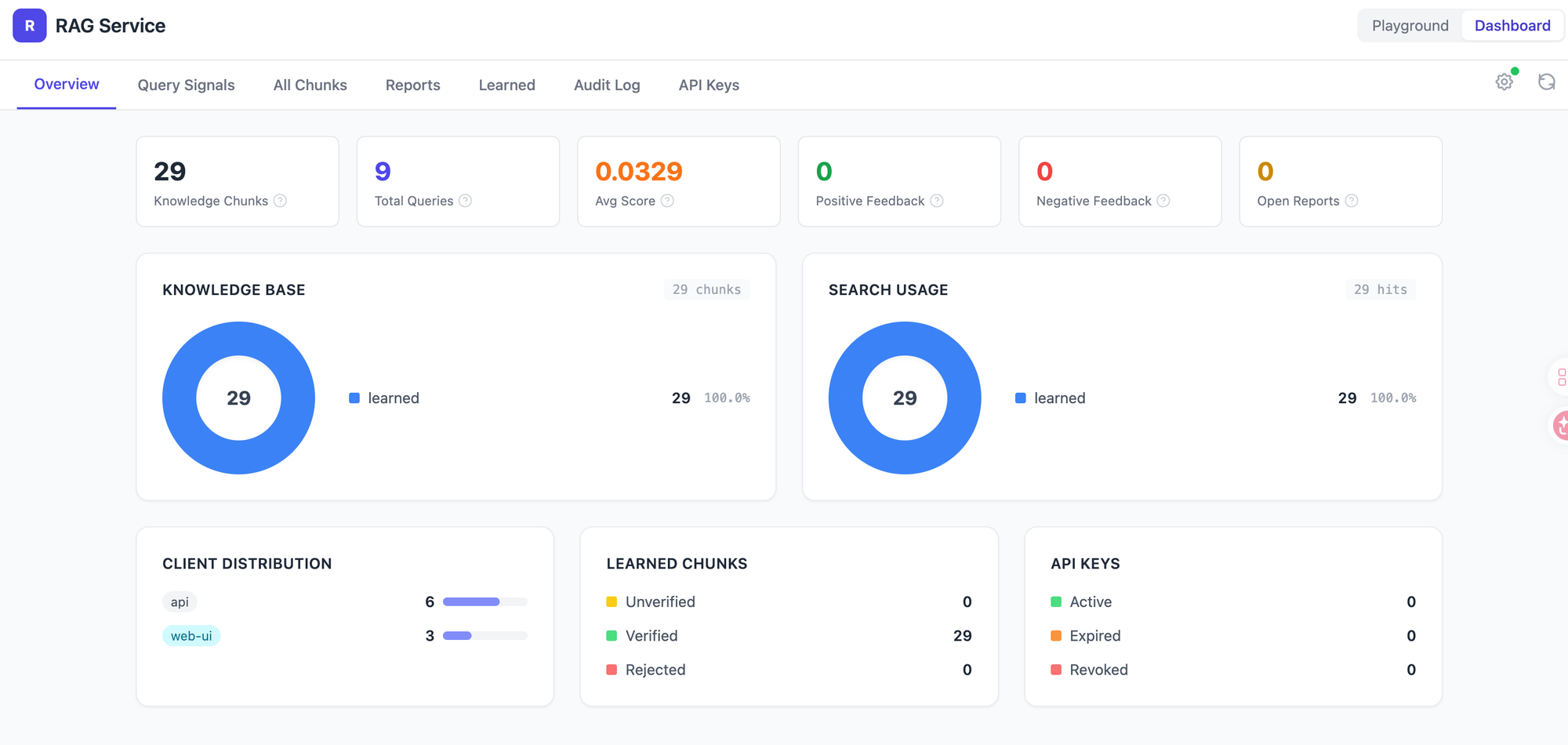
// 現今
// 更有趣
最聰明 vs. 夠可控
歡迎會後一起交流。

Vita Chen
PM @ Zeabur